 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEAT Quantifies Implicit Associations in Text-to-Video Generator Sora and Reveals Challenges in Bias Mitigation
Jan 02, 2026Text-to-Video (T2V) generators such as Sora raise concerns about whether generated content reflects societal bias. We extend embedding-association tests from words and images to video by introducing the Video Embedding Association Test (VEAT) and Single-Category VEAT (SC-VEAT). We validate these methods by reproducing the direction and magnitude of associations from widely used baselines, including Implicit Association Test (IAT) scenarios and OASIS image categories. We then quantify race (African American vs. European American) and gender (women vs. men) associations with valence (pleasant vs. unpleasant) across 17 occupations and 7 awards. Sora videos associate European Americans and women more with pleasantness (both d>0.8). Effect sizes correlate with real-world demographic distributions: percent men and White in occupations (r=0.93, r=0.83) and percent male and non-Black among award recipients (r=0.88, r=0.99). Applying explicit debiasing prompts generally reduces effect-size magnitudes, but can backfire: two Black-associated occupations (janitor, postal service) become more Black-associated after debiasing. Together, these results reveal that easily accessible T2V generators can actually amplify representational harms if not rigorously evaluated and responsibly deployed.
Learning Explainable Dense Reward Shapes via Bayesian Optimization
Apr 22, 2025Current reinforcement learning from human feedback (RLHF) pipelines for large language model (LLM) alignment typically assign scalar rewards to sequences, using the final token as a surrogate indicator for the quality of the entire sequence. However, this leads to sparse feedback and suboptimal token-level credit assignment. In this work, we frame reward shaping as an optimization problem focused on token-level credit assignment. We propose a reward-shaping function leveraging explainability methods such as SHAP and LIME to estimate per-token rewards from the reward model. To learn parameters of this shaping function, we employ a bilevel optimization framework that integrates Bayesian Optimization and policy training to handle noise from the token reward estimates. Our experiments show that achieving a better balance of token-level reward attribution leads to performance improvements over baselines on downstream tasks and finds an optimal policy faster during training. Furthermore, we show theoretically that explainability methods that are feature additive attribution functions maintain the optimal policy as the original reward.
Large Language Models: A New Approach for Privacy Policy Analysis at Scale
May 31, 2024



The number and dynamic nature of web and mobile applications presents significant challenges for assessing their compliance with data protection laws. In this context, symbolic and statistical Natural Language Processing (NLP) techniques have been employed for the automated analysis of these systems' privacy policies. However, these techniques typically require labor-intensive and potentially error-prone manually annotated datasets for training and validation. This research proposes the application of Large Language Models (LLMs) as an alternative for effectively and efficiently extracting privacy practices from privacy policies at scale. Particularly, we leverage well-known LLMs such as ChatGPT and Llama 2, and offer guidance on the optimal design of prompts, parameters, and models, incorporating advanced strategies such as few-shot learning. We further illustrate its capability to detect detailed and varied privacy practices accurately. Using several renowned datasets in the domain as a benchmark, our evaluation validates its exceptional performance, achieving an F1 score exceeding 93%. Besides, it does so with reduced costs, faster processing times, and fewer technical knowledge requirements. Consequently, we advocate for LLM-based solutions as a sound alternative to traditional NLP techniques for the automated analysis of privacy policies at scale.
Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning
Oct 14, 2022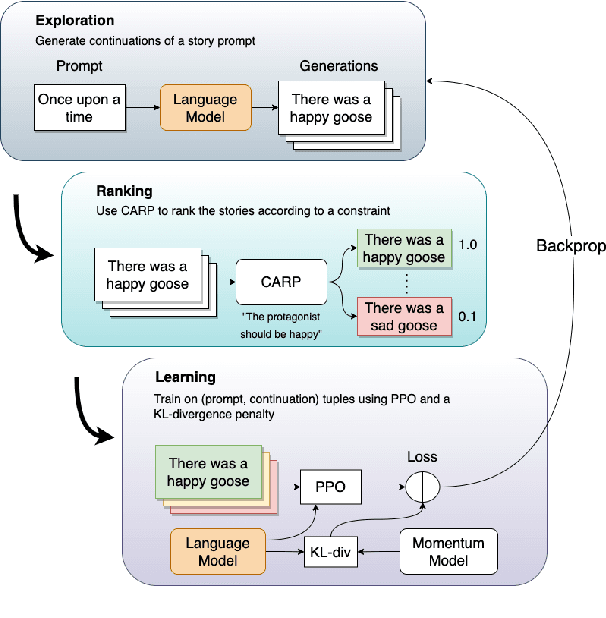

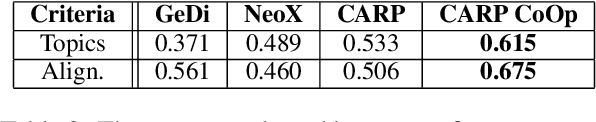
Controlled automated story generation seeks to generate natural language stories satisfying constraints from natural language critiques or preferences. Existing methods to control for story preference utilize prompt engineering which is labor intensive and often inconsistent. They may also use logit-manipulation methods which require annotated datasets to exist for the desired attributes. To address these issues, we first train a contrastive bi-encoder model to align stories with corresponding human critiques, named CARP, building a general purpose preference model. This is subsequently used as a reward function to fine-tune a generative language model via reinforcement learning. However, simply fine-tuning a generative language model with a contrastive reward model does not always reliably result in a story generation system capable of generating stories that meet user preferences. To increase story generation robustness we further fine-tune the contrastive reward model using a prompt-learning technique. A human participant study is then conducted comparing generations from our full system, ablations, and two baselines. We show that the full fine-tuning pipeline results in a story generator preferred over a LLM 20x as large as well as logit-based methods. This motivates the use of contrastive learning for general purpose human preference modeling.